MetaCLIP: pushing past the limits of CLIP — a comprehensive insight

In the ever-changing field of artificial intelligence, OpenAI’s CLIP has undeniably stood out as a pivotal model, seamlessly connecting text and images. It has unlocked new potentials and paved the way for multimodal advancements, exemplified by models like OWL-ViT and DALL-E.
Now, MetaCLIP, the refined version from MetaAI, enters the stage, promising to push boundaries even further. For those fascinated by CLIP’s capabilities, the introduction of MetaCLIP is a moment of heightened interest.
Following a concise review of CLIP and an introduction to MetaCLIP, we’ll directly assess MetaCLIP’s performance, exploring whether it represents a significant leap forward and evaluating its achievements in comparison to its predecessor, OpenAI CLIP.
CLIP: a paradigm shift
To grasp the essence of MetaCLIP, it is essential to comprehend the intricacies of CLIP. While detailed resources are available online, I recommend CLIP’s Github page and the CLIP paper from OpenAI.
The graph below illustrates the application of contrastive learning in training the model:
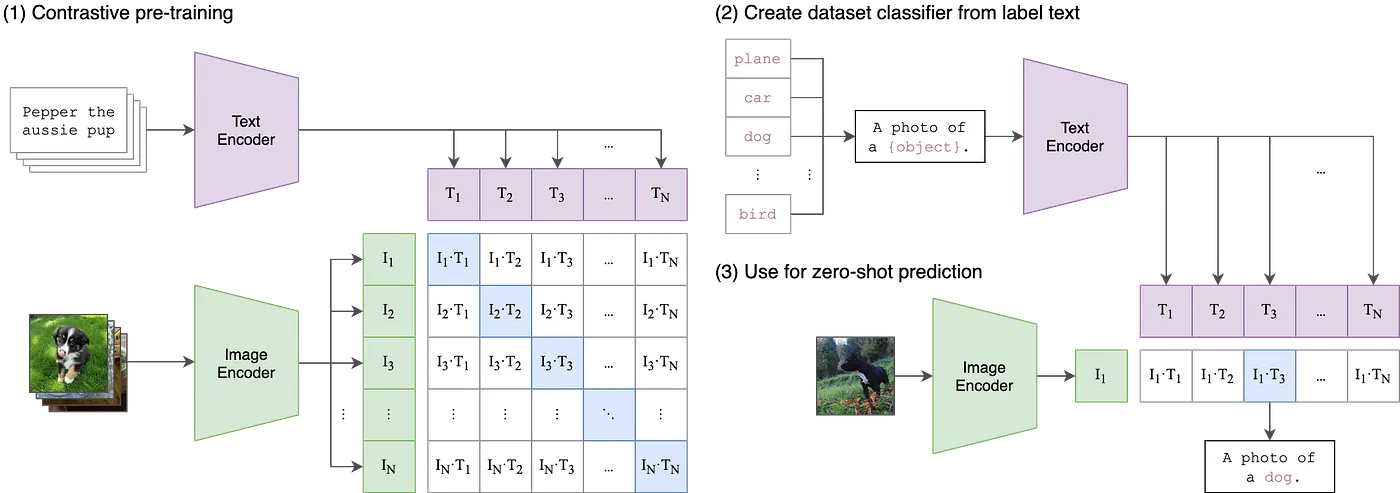
In essence, CLIP has redefined the landscape by introducing zero-shot learning to computer vision. Imagine a model empowered to excel on data it has never encountered during training — a transformative capability. Unlike traditional methods that necessitated training on specific objects, CLIP showcases the remarkable ability to recognize a diverse array of elements without the need for fine-tuning. This marks a pivotal departure from traditional approaches and lays the foundation for the advancements we’ll explore with MetaCLIP.
A step forward with MetaCLIP
According to the paper Demystifying CLIP data:
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP’s data by filtering with its model parameters. In this work, we intend to reveal CLIP’s data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP’s concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP’s data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP’s 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles.
What elevates MetaCLIP to a significant advancement? As outlined in its paper, it outperforms the already impressive performance of CLIP. Our objective is now to understand the depth of this improvement and its potential real-world implications.
MetaCLIP’s practical applications + notebooks
Similar to CLIP, MetaCLIP boasts versatility in addressing various computer vision tasks, and the transition is seamless when using the Hugging Face Transformers implementation — just tweak a mere three lines of code when loading the model, tokenizer and processor.
Let’s dive into the practicalities:
Choosing the MetaCLIP model
MetaCLIP offers multiple versions, each with distinct characteristics — base16, base32, large, or huge — and a choice between 400 million or 2.5 billion parameters. This provides a spectrum of options, and for this experiment, we opt for the base16–2.5B model. With a modest size of 600MB and an embedding dimensionality of 512, it stands as an apt comparison to the base16 version of OpenAI CLIP.
Setting up the environment
To run MetaCLIP, it is recommended to use a virtual environment and install the following dependencies:
virtualenv venv
source venv/bin/activate
pip install transformers torch
#Install FAISS to store embeddings. Uncomment one of the 2 options below
#pip install faiss-cpu
#pip install faiss-gpu
#Other packages not mandatory but useful for the examples you will find below
pip install datasets matplotlib scikit-learnTransitioning from CLIP to MetaCLIP
When using Hugging Face, the sole modification required in your code is adjusting how you load the model; the rest can remain unchanged.
- Loading CLIP:
from transformers import AutoProcessor, CLIPModel, AutoTokenizer
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32", torch_dtype=torch.float16)
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device)
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch32")- Loading MetaCLIP:
from transformers import AutoProcessor, AutoModelForZeroShotImageClassification, AutoTokenizer
processor = AutoProcessor.from_pretrained("facebook/metaclip-b16-fullcc2.5b")
model = AutoModelForZeroShotImageClassification.from_pretrained("facebook/metaclip-b16-fullcc2.5b", torch_dtype=torch.float16).to(device)
tokenizer = AutoTokenizer.from_pretrained("facebook/metaclip-b16-fullcc2.5b")Practical applications
- Classification
Classifying images with [Meta]CLIP is remarkably straightforward. You can easily expand your list of classes, and it’s worth noting that, due to its zero-shot prediction capabilities, [Meta]CLIP can accommodate any types of classes while delivering excellent performance.
Explore classification with a dataset in this notebook.
- Image retrieval with prompts
Searching images with prompts proves exceptionally useful. The process involves extracting embeddings for all images, storing them in a vector database, and using prompts to search and retrieve the top-k images with the highest similarity.
For implementation details, refer to this notebook.
- Image similarity
Discovering similar images follows a parallel process to image retrieval with prompts. The distinction lies in extracting the embeddings of input images instead of prompts.
Delve into this notebook for a concrete implementation.
- Image clustering
When combining [Meta]CLIP with FAISS, clustering images becomes a streamlined task. Repeat the familiar steps — extract image embeddings, store them in a vector database, utilize FAISS to define the number of clusters, and initiate clustering with ease.
For step-by-step guidance, consult this notebook.
CLIP VS MetaCLIP: a benchmarking approach
It’s time to scrutinize whether MetaCLIP surpasses its predecessor. Let’s compare their performances across the tasks we’ve outlined.
Image classification
To gauge their prowess in image classification, we subjected both CLIP and MetaCLIP to a benchmarking process using the CIFAR-10 dataset. This dataset comprises images classified into 10 distinct categories, each with a modest size of 32x32 pixels.



As demonstrated, MetaCLIP outshines CLIP in this benchmark.
Image retrieval with prompts
To compare their performance, we used the validation set of the COCO dataset containing 5000 images. Our objective is to qualitatively assess their performance in retrieving the top-3 images given a specific prompt.
- Assessing OCR capabilities
Prompt: “Clean and dry”

Only MetaCLIP finds the vehicle with the inscription “ Clean and dry” .
Prompt: “Procter2”
“Procter2" is written on a sign in one of the 5.000 images of the dataset and we are looking to find it with both models. Here is the outcome:

MetaCLIP finds it in 2nd position while CLIP does not find it (even in its top-10).
- Assessing difficult prompts
Prompt: A baseball player wearing a jacket with a red J

MetaCLIP finds the right one in 1st position.
Prompt: a man looking at a mirror and screaming

CLIP finds the right image in 3rd position while MetaCLIP finds it in 1st position.
Comparing their performance on the validation set of the COCO dataset, MetaCLIP demonstrated higher precision in retrieving images with specific prompts and showcased superior OCR capabilities.
Image similarity
In our exploration of image similarity, we chose a subset of the DISC21 dataset to compare the performance of CLIP and MetaCLIP. The dataset was meticulously crafted by transforming reference images through a variety of alterations to generate query images. The ultimate objective was to navigate through a vast collection of images (1 million) and accurately identify the corresponding reference image for each query.

For our evaluation, we utilized a subset featuring 100,000 reference images and 1,000 query images. For each query image, we attempted to find the corresponding reference image, and we assessed the results using two key metrics:
- Accuracy: the ratio of correctly predicted images to the total number of images.
- Top-3 Accuracy: the ratio of times the correct image is found within the top three similar images to the total number of images.
Without further ado, let’s unveil the outcomes:

- Examining the results
1 — CLIP finding the reference, but not MetaCLIP

2 — MetaCLIP finding the reference, but not CLIP

3 — MetaCLIP finding the reference in its top-3, but not CLIP

Exploring image similarity using a subset of the DISC21 dataset, MetaCLIP emerged as the front runner. The precision of MetaCLIP was notably higher compared to CLIP, evident in accurate reference image identification and top-3 accuracy.
Image clustering
Leveraging FAISS and the CIFAR10 dataset, we created 10 clusters (as there are 10 different classes) and meticulously analyzed the distribution of classes within each cluster. We compare the confusion matrix, homogeneity, completeness and V measure.
For the reminder:
- Homogeneity measures how well each cluster contains only members of a single class
- Completeness measures how well all members of a given class are assigned to the same cluster.
- V-measure is the harmonic mean of homogeneity and completeness.
These scores range from 0 to 1, with 1 indicating perfect clustering.



Again, MetaCLIP outperforms CLIP in this benchmark.
Conclusion
As validated by the benchmarking conducted, MetaCLIP indisputably emerges as a refined iteration of CLIP, a model already revered for its potency in computer vision tasks.
For current CLIP users, transitioning to MetaCLIP is not only appealing but also seamless, requiring minimal code adjustments, particularly for those utilizing the Transformers library.
Link to notebooks:
- Classification: https://github.com/jeremy-k3/notebooks/blob/main/MetaCLIP/MetaCLIP_Classification.ipynb
- Image similarity: https://github.com/jeremy-k3/notebooks/blob/main/MetaCLIP/MetaCLIP_image_similarity.ipynb
- Image retrieval with prompts: https://github.com/jeremy-k3/notebooks/blob/main/MetaCLIP/MetaCLIP_image_retrieval.ipynb
- Clustering: https://github.com/jeremy-k3/notebooks/blob/main/MetaCLIP/MetaCLIP_clustering.ipynb
